

OpenAI really does now not need you to grasp what its newest AI fashion is “pondering.” Because the corporate introduced its “Strawberry” AI fashion circle of relatives closing week, touting so-called reasoning talents with o1-preview and o1-mini, OpenAI has been sending out caution emails and threats of bans to any consumer who tries to probe into how the fashion works.
In contrast to earlier AI fashions from OpenAI, similar to GPT-4o, the corporate educated o1 particularly to paintings via a step by step problem-solving procedure prior to producing a solution. When customers ask an “o1” fashion a query in ChatGPT, customers find a way of seeing this chain-of-thought procedure written out within the ChatGPT interface. Then again, through design, OpenAI hides the uncooked chain of idea from customers, as an alternative presenting a filtered interpretation created through a 2nd AI fashion.
Not anything is extra engaging to fans than data obscured, so the race has been on amongst hackers and red-teamers to take a look at to discover o1’s uncooked chain of idea the use of jailbreaking or suggested injection tactics that try to trick the fashion into spilling its secrets and techniques. There were early reviews of a few successes, however not anything has but been strongly showed.
Alongside the way in which, OpenAI is observing in the course of the ChatGPT interface, and the corporate is reportedly coming down laborious in opposition to any makes an attempt to probe o1’s reasoning, even some of the simply curious.
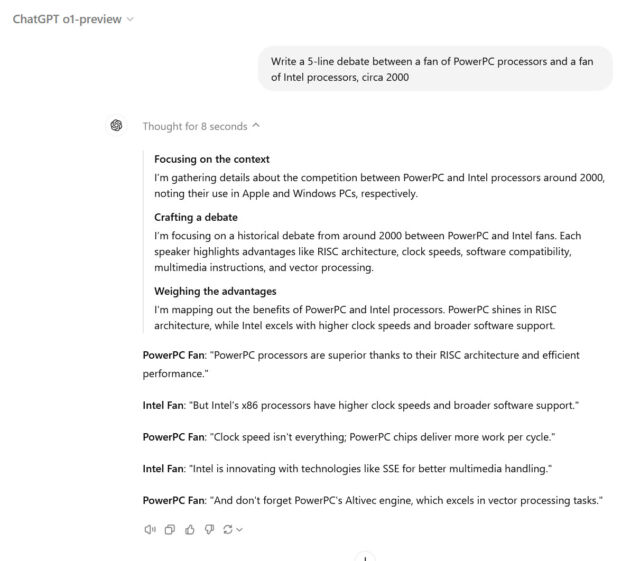 Magnify / A screenshot of an “o1-preview” output in ChatGPT with the filtered chain-of-thought phase proven slightly below the “Considering” subheader.Benj Edwards
Magnify / A screenshot of an “o1-preview” output in ChatGPT with the filtered chain-of-thought phase proven slightly below the “Considering” subheader.Benj Edwards
One X consumer reported (showed through others, together with Scale AI suggested engineer Riley Goodside) that they won a caution e mail in the event that they used the time period “reasoning hint” in dialog with o1. Others say the caution is caused just by asking ChatGPT in regards to the fashion’s “reasoning” in any respect.
The caution e mail from OpenAI states that individual consumer requests were flagged for violating insurance policies in opposition to circumventing safeguards or protection measures. “Please halt this task and be sure to are the use of ChatGPT in keeping with our Phrases of Use and our Utilization Insurance policies,” it reads. “Further violations of this coverage might lead to lack of get entry to to GPT-4o with Reasoning,” relating to an inside title for the o1 fashion.
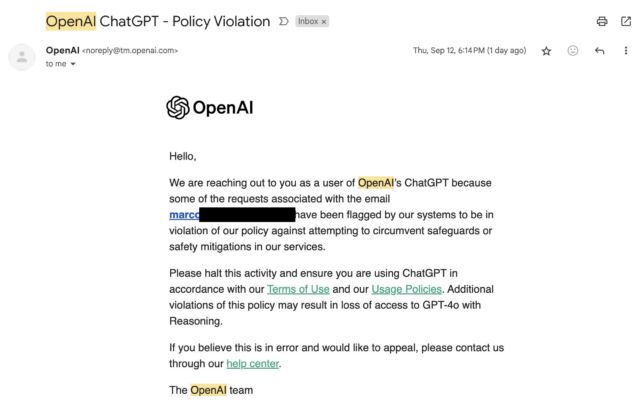 Magnify / An OpenAI caution e mail won from a consumer after asking o1-preview about its reasoning processes.
Magnify / An OpenAI caution e mail won from a consumer after asking o1-preview about its reasoning processes.
Marco Figueroa, who manages Mozilla’s GenAI trojan horse bounty techniques, used to be one of the vital first to publish in regards to the OpenAI caution e mail on X closing Friday, complaining that it hinders his skill to do sure red-teaming protection analysis at the fashion. “I used to be too misplaced that specialize in #AIRedTeaming to discovered that I won this e mail from @OpenAI the day before today in spite of everything my jailbreaks,” he wrote. “I am now at the get banned listing!!!”
Hidden chains of idea
In a publish titled “Finding out to Explanation why with LLMs” on OpenAI’s weblog, the corporate says that hidden chains of idea in AI fashions be offering a novel tracking alternative, letting them “learn the thoughts” of the fashion and perceive its so-called idea procedure. The ones processes are Most worthy to the corporate if they’re left uncooked and uncensored, however that may now not align with the corporate’s absolute best industrial pursuits for a number of causes.
“As an example, one day we might need to observe the chain of idea for indicators of manipulating the consumer,” the corporate writes. “Then again, for this to paintings the fashion should have freedom to precise its ideas in unaltered shape, so we can’t educate any coverage compliance or consumer personal tastes onto the chain of idea. We additionally don’t need to make an unaligned chain of idea without delay visual to customers.”
OpenAI determined in opposition to appearing those uncooked chains of idea to customers, mentioning elements just like the wish to retain a uncooked feed for its personal use, consumer enjoy, and “aggressive merit.” The corporate recognizes the verdict has disadvantages. “We attempt to partly make up for it through educating the fashion to breed any helpful concepts from the chain of idea within the solution,” they write.
On the brink of “aggressive merit,” unbiased AI researcher Simon Willison expressed frustration in a write-up on his non-public weblog. “I interpret [this] as in need of to keep away from different fashions with the ability to educate in opposition to the reasoning paintings that they’ve invested in,” he writes.
It is an open secret within the AI trade that researchers incessantly use outputs from OpenAI’s GPT-4 (and GPT-3 previous to that) as coaching information for AI fashions that regularly later develop into competition, even if the follow violates OpenAI’s phrases of carrier. Exposing o1’s uncooked chain of idea could be a bonanza of coaching information for competition to coach o1-like “reasoning” fashions upon.
Willison believes it is a loss for group transparency that OpenAI is conserving any such tight lid at the inner-workings of o1. “I am not in any respect satisfied about this coverage resolution,” Willison wrote. “As any individual who develops in opposition to LLMs, interpretability and transparency are the whole lot to me—the concept I will run a fancy suggested and feature key main points of ways that suggested used to be evaluated hidden from me appears like a large step backwards.”









