
The adaptation of this type-all inside the other GSM-Symbolic runs and in comparison to the result of GSM8K-is very unexpected since, because the researchers say, “the entire ideas essential to resolve the query stay the similar.” The truth that such small adjustments result in such variable effects suggests to researchers that those fashions don’t seem to be producing “fastened” hypotheses however quite “experimental.[ing] to create a an identical fashion, matching the questions and solution strategies with the similarities proven within the educational papers.” Do not be at a loss for words. Alternatively, the principle variations proven within the GSM-Symbolic exams had been steadily small. The primary object plot of OpenAI’s ChatGPT-4o, for instance, has dropped from from 95.2 % accuracy on GSM8K to an outstanding 94.9 % on GSM-Symbolic is the best possible ranking the usage of the benchmark, without reference to whether or not or no longer the fashion itself makes use of “usual” good judgment at the back of the scenes (even though the full accuracy of maximum fashions dropped considerably when the researchers added one or two additional steps for issues).

An instance of the way some fashions are misled via needless data added to the GSM8K benchmark suite. An instance of the way some fashions are misled via needless data added to the GSM8K benchmark suite. Credit score: Apple Analysis The LLMs examined did worse, when Apple researchers changed the GSM-Symbolic benchmark via including “phrases that appear necessary however don’t seem to be essential” to the questions. For this “GSM-NoOp” (quick for “no operation”) benchmark, the query about what number of kiwis an individual alternatives in a couple of days can also be modified to incorporate the precise “5 of them. [the kiwis] had been smaller than moderate.” Including those purple herrings ended in what the researchers referred to as a “dramatic drop” in accuracy in comparison to GSM8K, starting from 17.5 % to 65.7 %, relying at the fashion examined. The accuracy highlights the constraints of the usage of “fashion comparisons.” it is simple to “flip phrases to paintings with out working out their that means,” the researchers wrote.
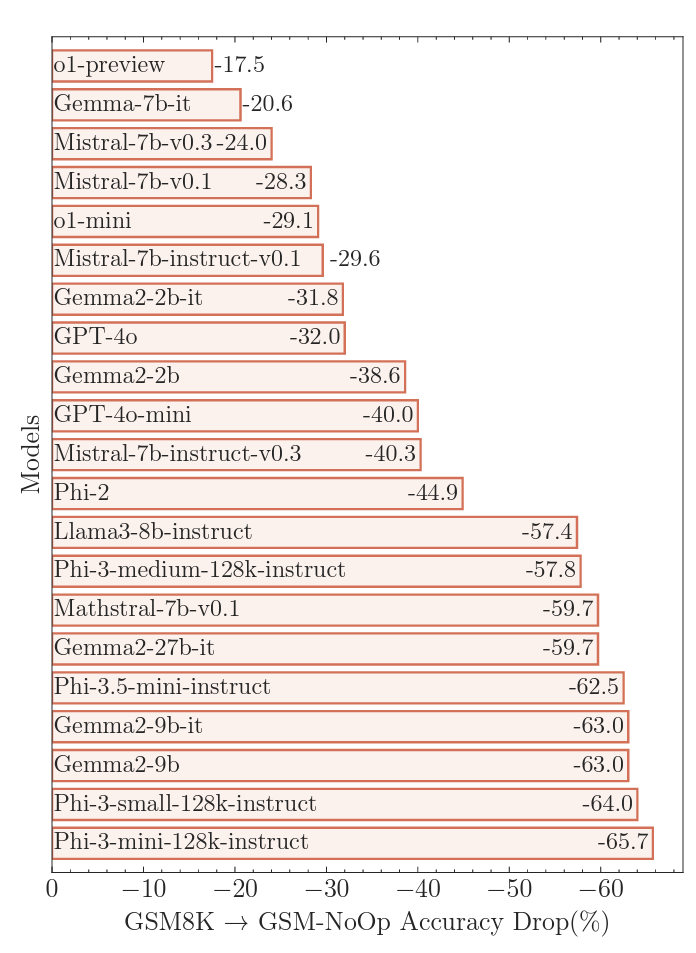
Giving meaningless data to what steadily ends up in “disastrous” failure for lots of “conversational” LLMs Giving meaningless data to what steadily ends up in “catastrophic” failure for lots of “ideological” LLMs Quote: Apple Analysis Within the instance with small kiwis, for instance, many fashions take a look at to take away small culmination from the overall quantity as a result of, the researchers suppose, “their coaching fabrics had an identical fashions that require conversion to removing operations.” That is the kind of “giant mistake” that researchers say “offers deep concept.” [the models’] pondering” that can not be helped via right kind upkeep or different maintenance.












